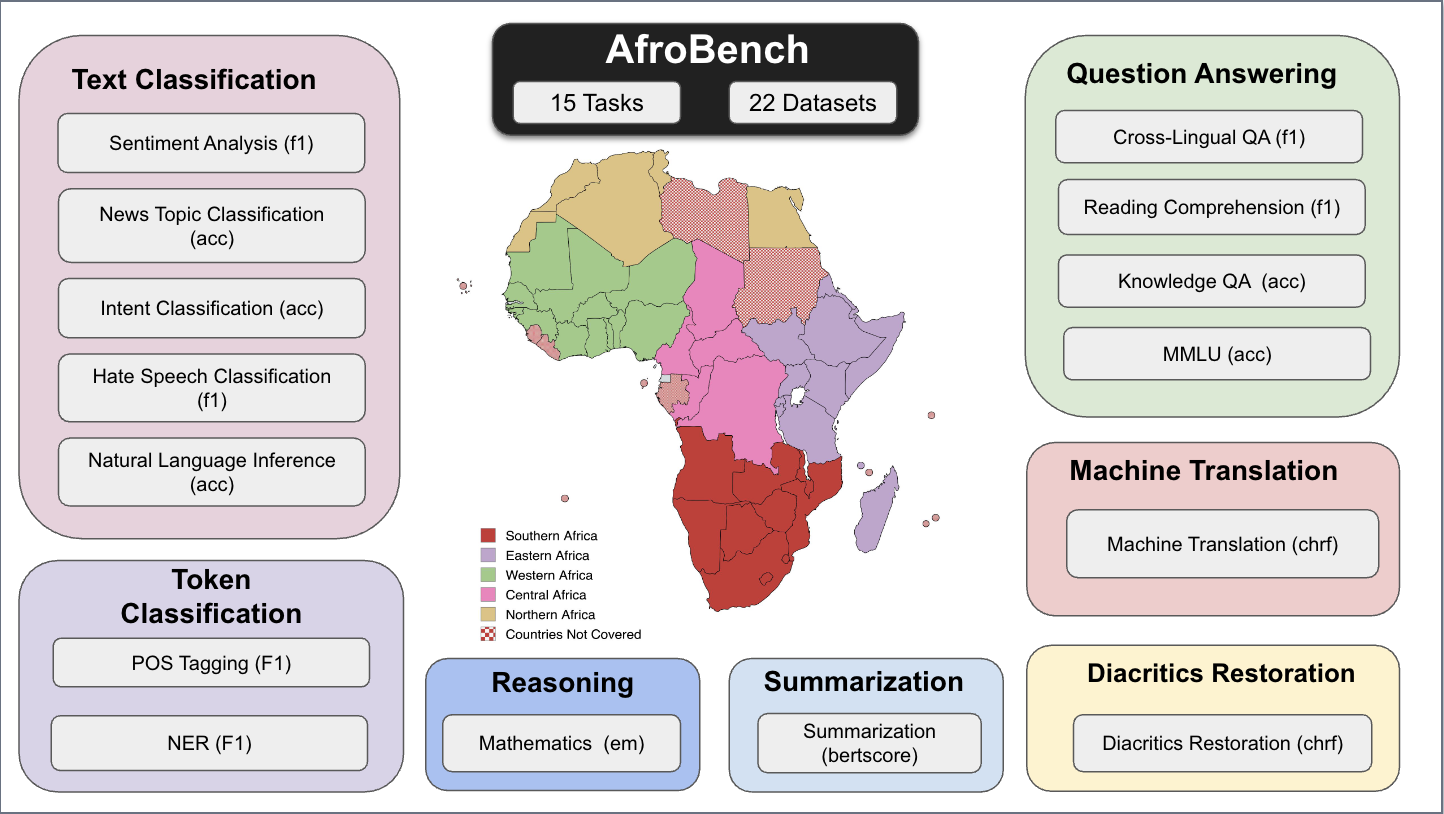
Figure: Overview of 15 NLP tasks and 22 datasets covered in AfroBench.
Evaluating 64 African languages across 15 NLP tasks and 22 Datasets.
AfroBench is a comprehensive benchmark for evaluating large language models (LLMs) on African languages, covering translation, question answering, text classification, and more.
Evaluating diverse African languages for NLP fairness.
From machine translation to sentiment analysis.
Evaluation scripts configured in lm-eval-harness for reproducible benchmarking.
Figure: Overview of 15 NLP tasks and 22 datasets covered in AfroBench.
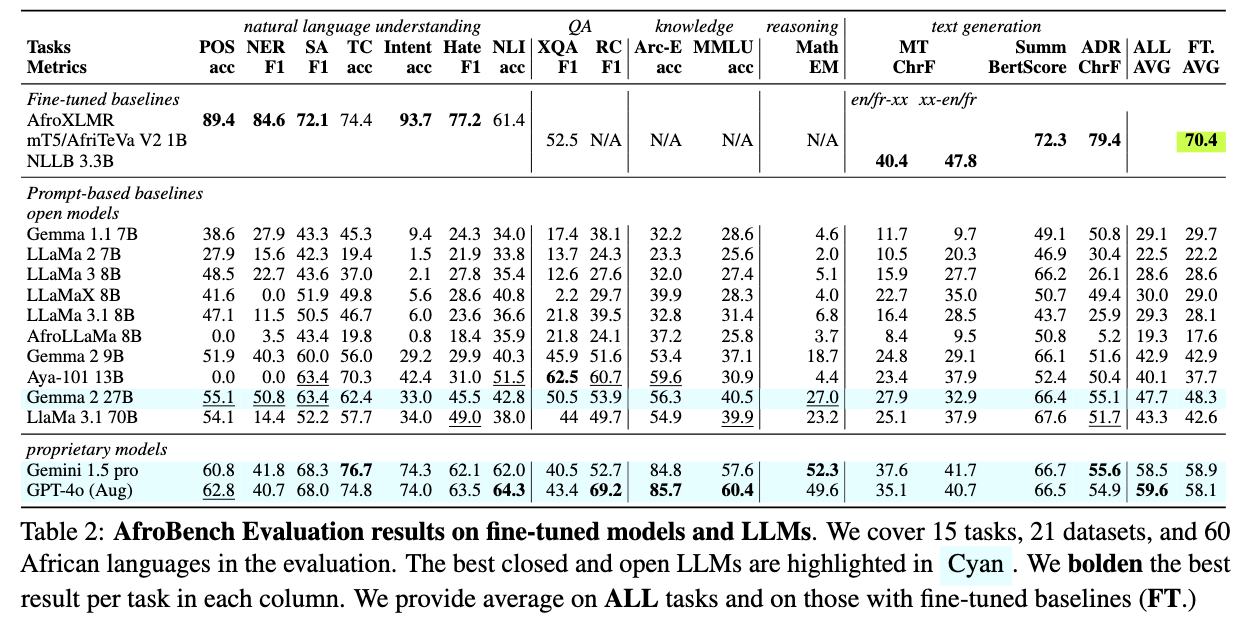
Large-scale multilingual evaluations, such as MEGA, often include only a handful of African languages due to the scarcity of high-quality evaluation data and the limited discoverability of existing African datasets. This lack of representation hinders comprehensive LLM evaluation across a diverse range of languages and tasks. To address these challenges, we introduce AfroBench—a multi-task benchmark for evaluating the performance of LLMs across 64 African languages, 15 tasks and 22 datasets. AfroBench consists of nine natural language understanding datasets, five text generation datasets, five knowledge and question answering tasks, and one mathematical reasoning task. We present results comparing the performance of prompting LLMs to fine-tuned baselines based on BERT and T5-style models. Our results suggest large gaps in performance between high-resource languages, such as English, and African languages across most tasks; but performance also varies based on the availability of monolingual data resources. Our findings confirm that performance on African languages continues to remain a hurdle for current LLMs, underscoring the need for additional efforts to close this gap.
AfroBench is the first comprehensive LLM benchmark for African languages, evaluating proprietary and open models across 15 NLP tasks, 22 datasets, and 64 languages. AfroBench challenges models beyond traditional benchmarks with tasks like mathematical reasoning and knowledge question answering (e.g. MMLU). The category of tasks covered are:
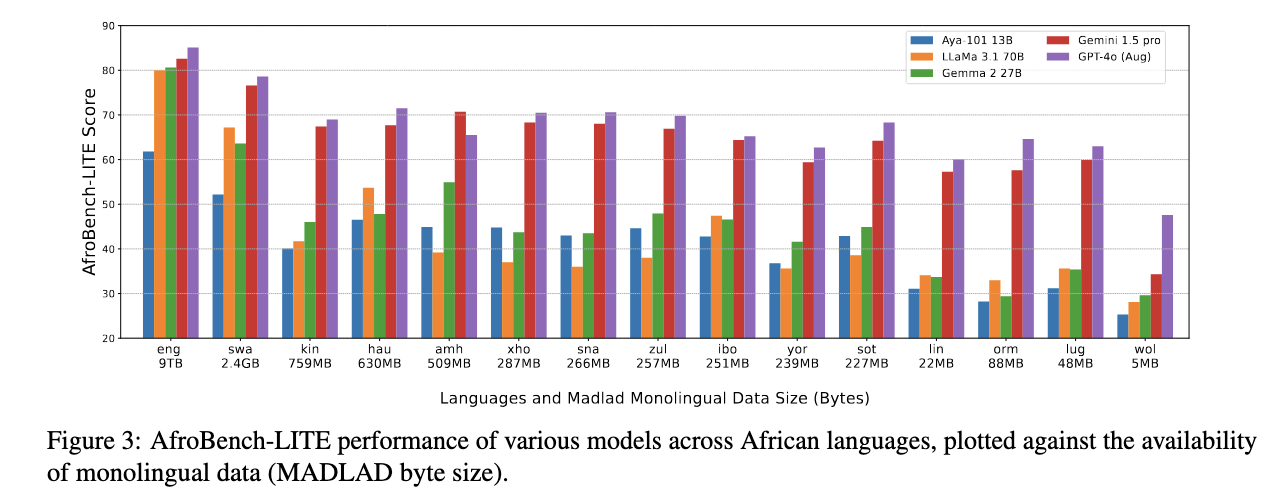
AfroBench provides critical insights into model performance across diverse linguistic landscapes. The results showcase the performance of various LLMs across different NLP tasks. Proprietary models such as GPT-4o and Gemini 1.5 Pro gave the overall best performance on average, followed by Gemma 2 27B——the best open model in our evaluation, exceeding the performance of LLaMa 3.1 70B with more than twice the parameter size as shown in the plot.
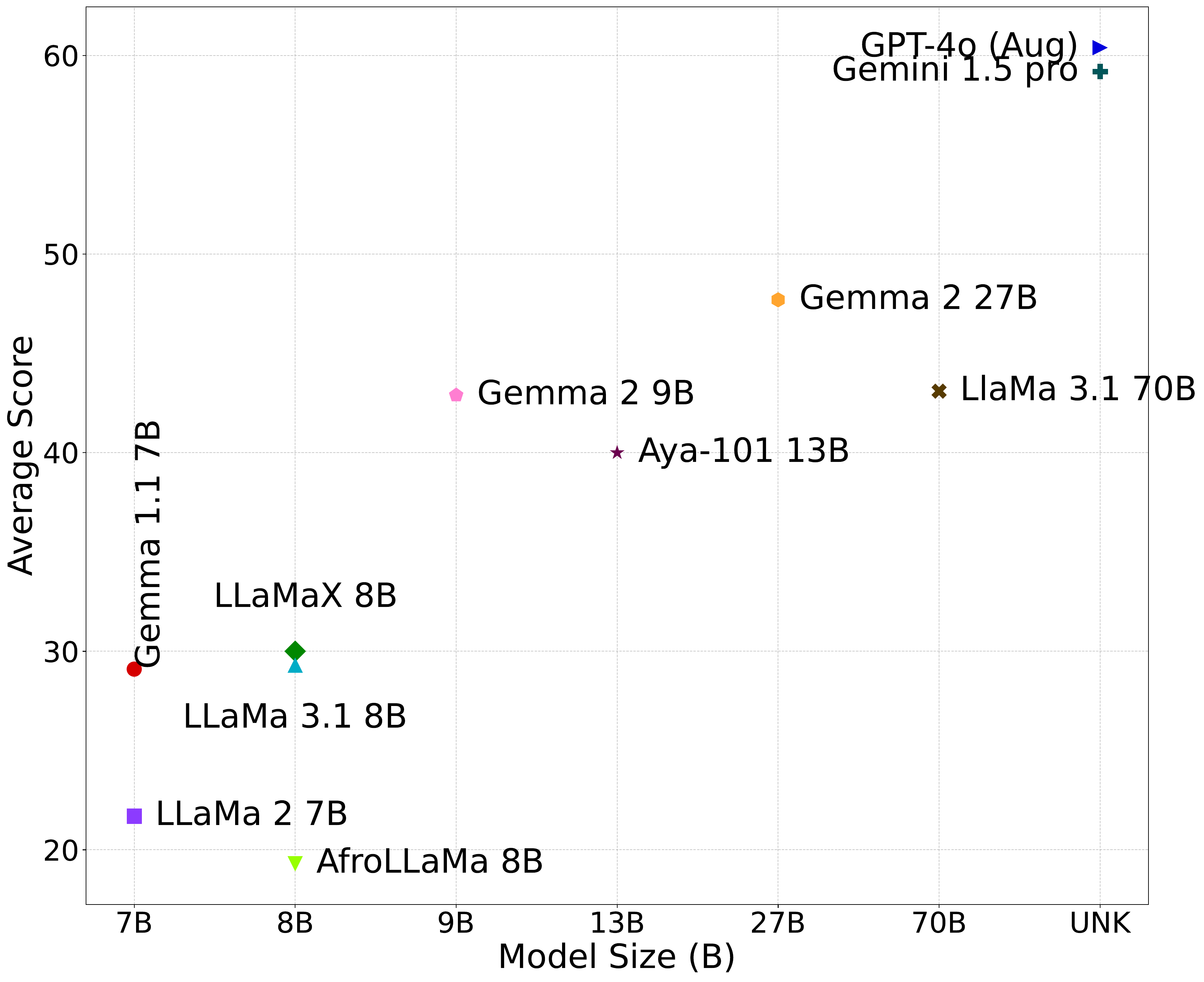
Figure: Comparison between AfroBench average score against model size.
AfroBench-LITE is a streamlined version of AfroBench, designed for comprehensive LLM evaluation under compute constraints. It establishes baselines across 7 datasets and 14 African languages, ensuring broad NLP coverage while maintaining language diversity.
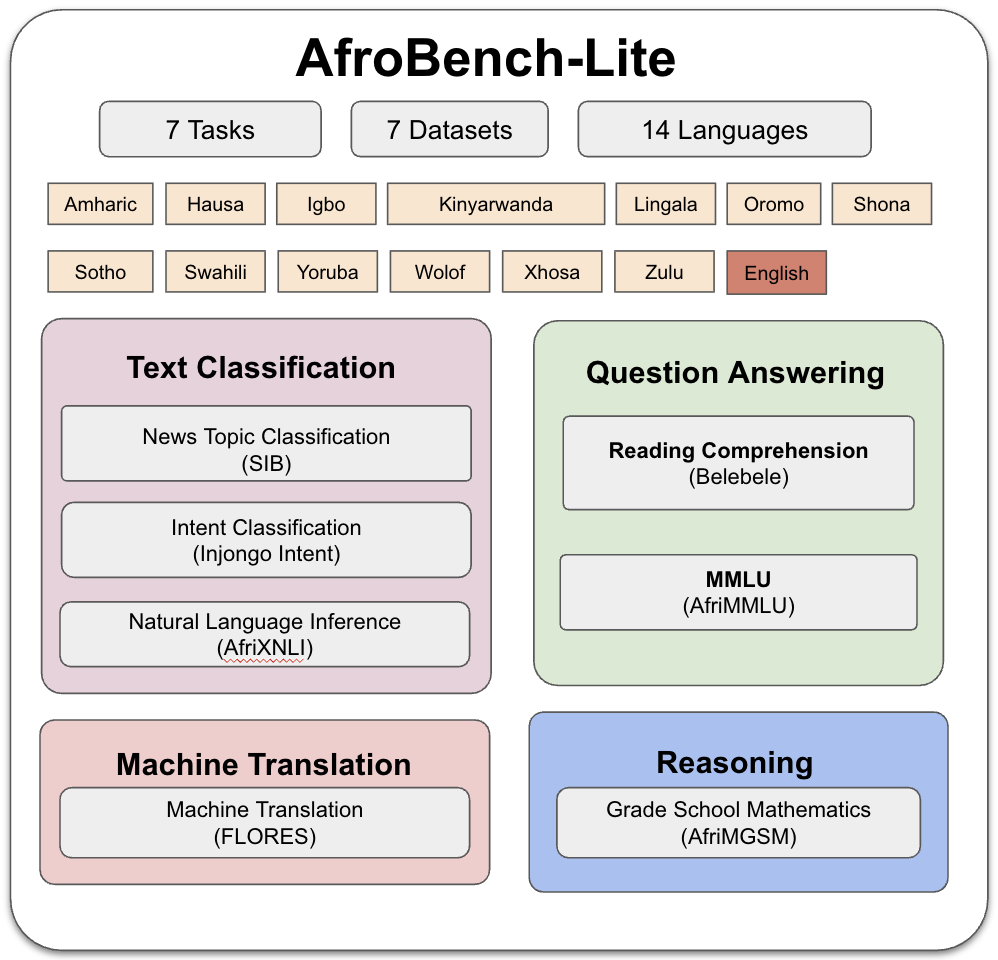
Figure: Overview of AfroBench-LITE tasks and languages
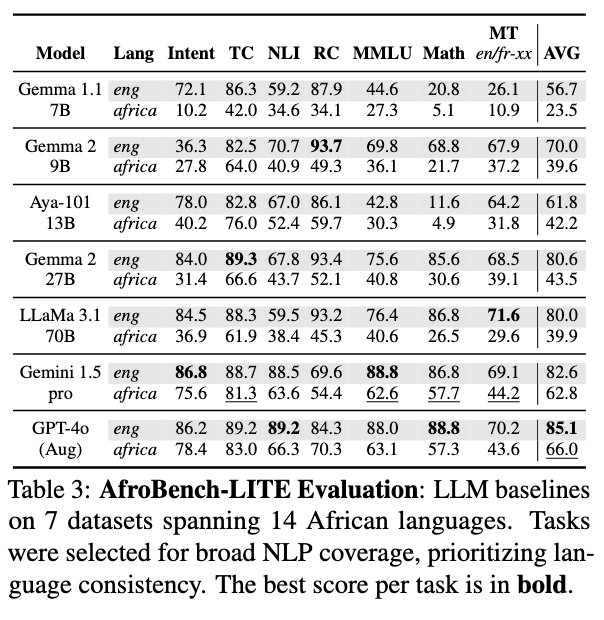
Figure: Comparison between AfroBench score against model size. Closed models tend to perform better, with GPT-4o and Gemini 1.5 Pro leading the benchmarks.
@misc{ojo2025afrobenchgoodlargelanguage,
title={AfroBench: How Good are Large Language Models on African Languages?},
author={Jessica Ojo and Odunayo Ogundepo and Akintunde Oladipo and Kelechi Ogueji and Jimmy Lin and Pontus Stenetorp and David Ifeoluwa Adelani},
year={2025},
eprint={2311.07978},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2311.07978},
}
Please cite the individual datasets used in this benchmark. References to the corresponding papers and datasets can be found in the tasks taxonomy.