Overview
Users interact with QA systems and leave feedback. In this project, we investigate methods of improving QA systems further post-deployment based on user interactions.
Dataset
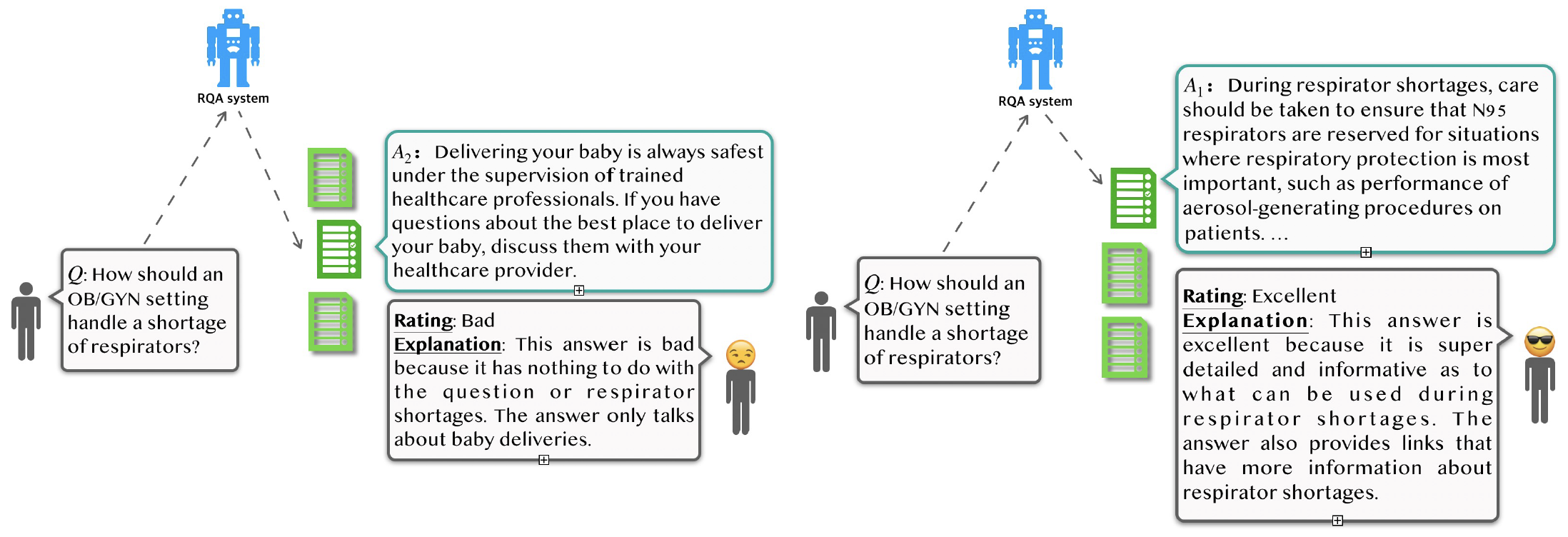
We collect a retrieval-based QA dataset, FeedbackQA, which contains interactive feedback from users. We collect this dataset by deploying a base QA system to crowdworkers who then engage with the system and provide feedback on the quality of its answers. The feedback contains both structured ratings and unstructured natural language explanations. Check the dataset explorer at the bottom for some real examples.
Methods
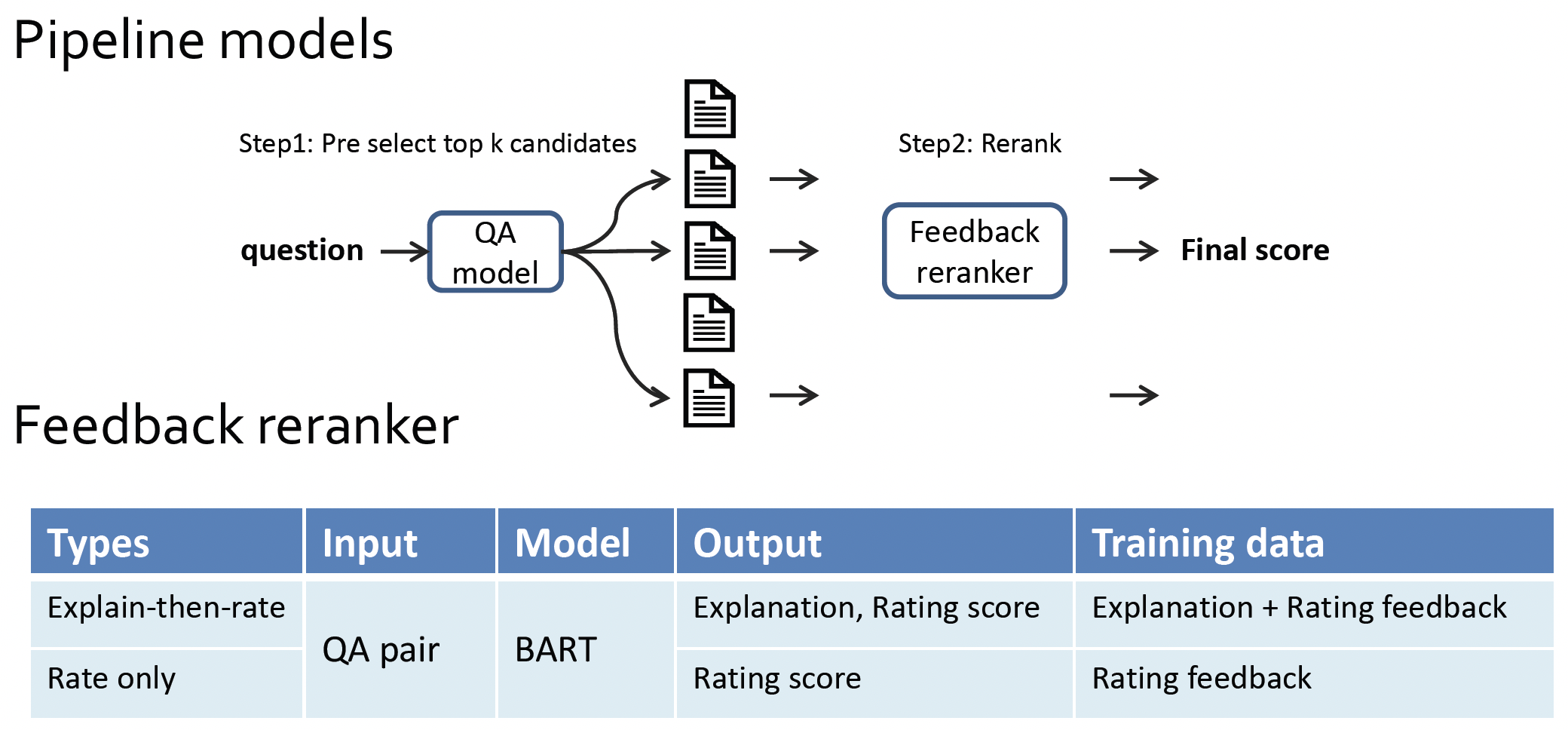
We propose a method to improve the RQA model with the feedback data, training a reranker to select an answer candidate as well as generate the explanation. We find that this approach not only increases the accuracy of the deployed model but also other stronger models for which feedback data is not collected. Moreover, our human evaluation results show that both human-written and model-generated explanations help users to make informed and accurate decisions about whether to accept an answer. Read our paper for more details, and play with our demo for an intuitive understanding of what we have done.
Dataset Explorer
Loading...