LLM2Vec Tutorial: Steps for transforming any decoder-only model into a text encoder
LLM2Vec consists of 3 simple steps to transform decoder-only LLMs into text encoders: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. After the LLM2Vec transformation, the model can be further fine-tuned with supervised data. Here, we provide a tutorial on how to use the LlaMA models.
This tutorial will focus on the first two steps. After completing these steps, the model can be trained for unsupervised or supervised contrastive learning like any other encoder model.
For the scope of this tutorial, we will showcase how to apply LLM2Vec to models from the LLaMA-2 model family. For simplicity, we focus on the FlashAttention attention implementation. The following steps have been tested using transformers version 4.39.3.
1) Enabling Bidirectional Attention
A decoder-only causal LLM consists of multiple decoder layers, each of which has a self-attention sub-layer.
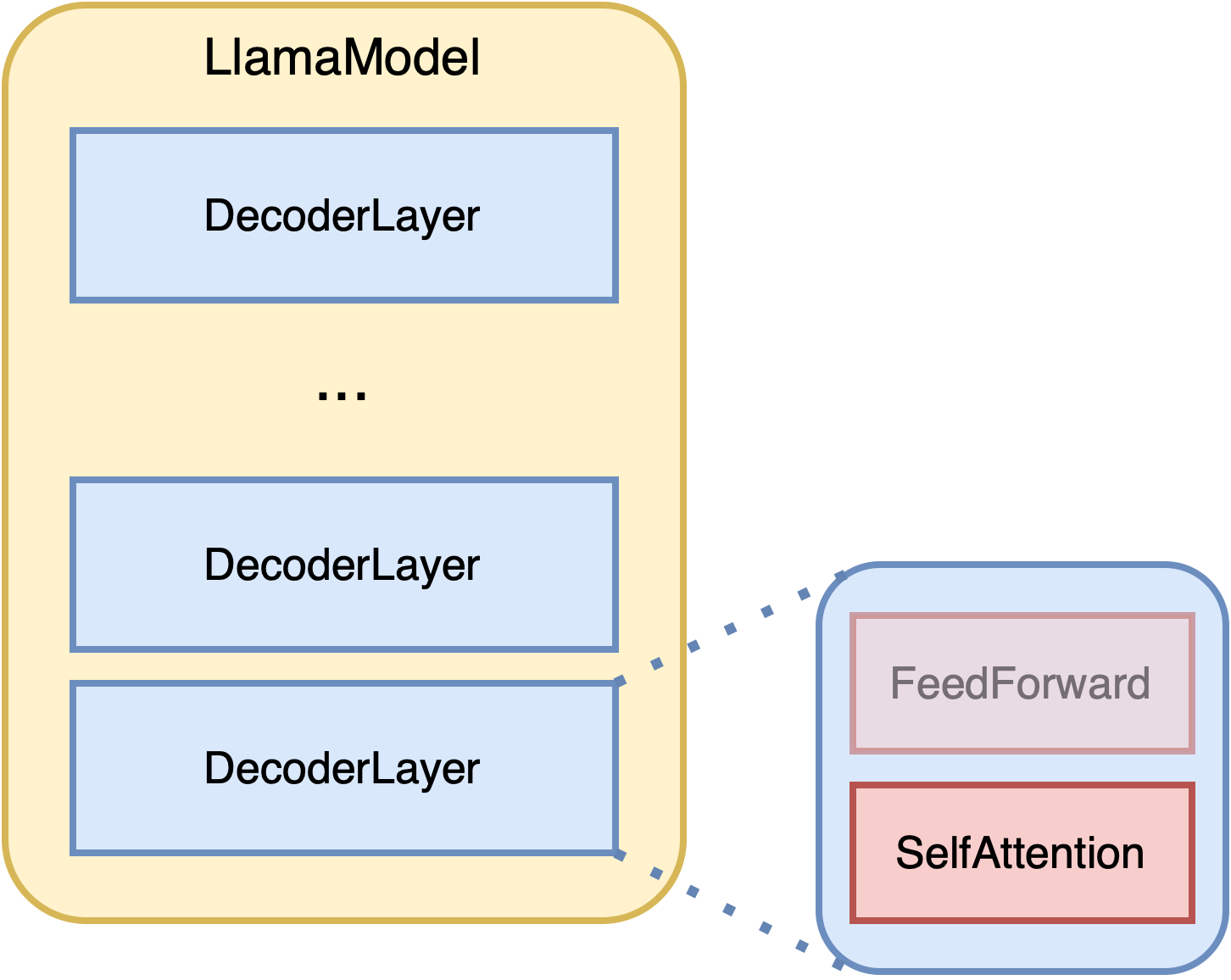
We start bottoms-up by first modifying the attention mechanism to be bidirectional.
HuggingFace implements three attention mechanisms for Llama and Mistral models - Eager, SDPA, and Flash Attention. Here, we only modify the flash attention implementation. In order to be able to use the bidirectional attention, we need to create new LLaMA flash attention class:
class ModifiedLlamaFlashAttention2(LlamaFlashAttention2):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.is_causal = False # Initially `True` in transformers implementation
LLAMA_ATTENTION_CLASSES = {
"eager": LlamaAttention,
"flash_attention_2": ModifiedLlamaFlashAttention2, # Initially, `LlamaFlashAttention2'
"sdpa": LlamaSdpaAttention,
}
We have changed flash attention to be non-causal (i.e., bidirectional). Next, we need to modify the decoder layer to use this new attention classes. the __init__ function is directly copied from the transformers implementation of LlamaDecoderLayer. As flash_attention_2 in LLAMA_ATTENTION_CLASSES points to the new flash attention class, the decoder layer will use bidirectional attention when initialized with flash_attention_2.
class ModifiedLlamaDecoderLayer(LlamaDecoderLayer):
def __init__(self, config: LlamaConfig, layer_idx: int):
nn.Module.__init__(self) # Initially, super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = LLAMA_ATTENTION_CLASSES[config._attn_implementation](config=config, layer_idx=layer_idx)
self.mlp = LlamaMLP(config)
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
Finally, we need to modify the main model class to use the new decoder layer. We create a new model class LlamaBiModel that inherits from LlamaModel and uses the new ModifiedLlamaDecoderLayer in its __init__ function. Everything else remains the same as the original implementation of LlamaModel.
class LlamaBiModel(LlamaModel):
def __init__(self, config):
LlamaPreTrainedModel.__init__(self, config) # Initially, super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[ModifiedLlamaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)] # Initially, `LlamaDecoderLayer(config, layer_idx)`
)
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.gradient_checkpointing = False
self.post_init()
That’s it! We have successfully created a bidirectional LLaMA model. We can now use this model for training with masked next token prediction.
2) Masked Next Token Prediction (MNTP)
To train our models in masked next token prediction, we again implement a wrapper model class on top of LlamaForCausalLM class with LlamaBiModel as backbone.
The default LlamaForCausalLM class object has a model attribute that is an instance of LlamaModel. We will replace this model with our new LlamaBiModel.
class BiLlamaForMNTP(LlamaForCausalLM):
def __init__(self, config, attention_dropout=0.0):
LlamaPreTrainedModel.__init__(self, config) # Initially, super().__init__(config)
self.model = LlamaBiModel(config) # Initially, LlamaModel(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.post_init()
We can now use this model for training with masked next token prediction.
In our work, predicting a masked token at position i, we compute the loss based on the logits obtained from the token representation at the previous position i-1. This shifting is automatically handled by the forward function of LlamaForCausalLM as similar shifting is required in the next token prediction task.
# Code snippet from LlamaForCausalLM.forward()
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
shift_logits = shift_logits.view(-1, self.config.vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
loss = loss_fct(shift_logits, shift_labels)
For training, we adapt the huggingface example script for masked language modeling - examples/pytorch/language-modeling/run_mlm.py. The only change required is to define a mask token, as decoder-only models do not have a mask token by default. We can use the padding token as the mask token. In our work we used underscore _ as the mask token.
tokenizer.mask_token = "_"
The bi-directional LLaMA model can now be trained with masked next token prediction.
Conclusion
In this tutorial, we have shown how to enable bidirectional connections in a decoder-only LLM and train it with masked next token prediction (first two steps of LLM2Vec). The resulting model can be further fine-tuned with supervised data or used for unsupervised contrastive learning. To learn more about LLM2Vec, check out our project page.