
About WebLINX
WEBLINX is a large-scale benchmark of 100K interactions across 2300 expert demonstrations of conversational web navigation. Our benchmark covers a broad range of patterns on over 150 real-world websites and can be used to train and evaluate agents in diverse scenarios.

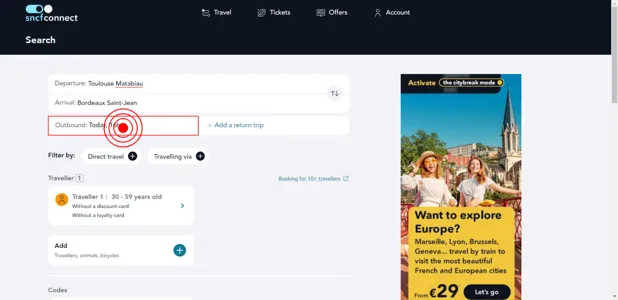
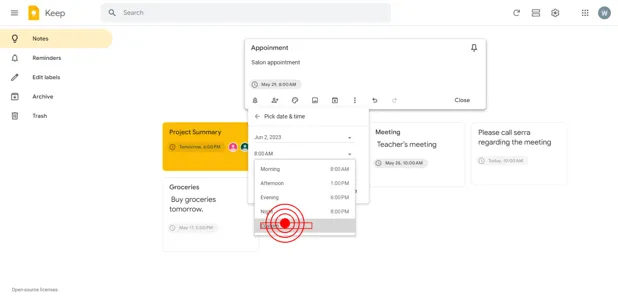
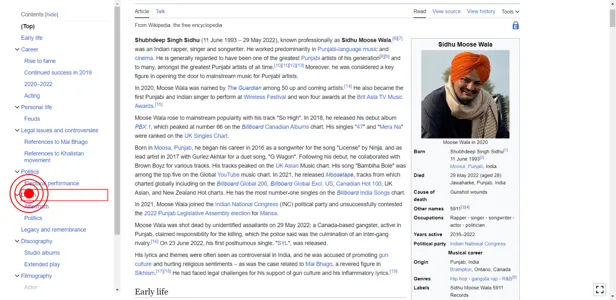
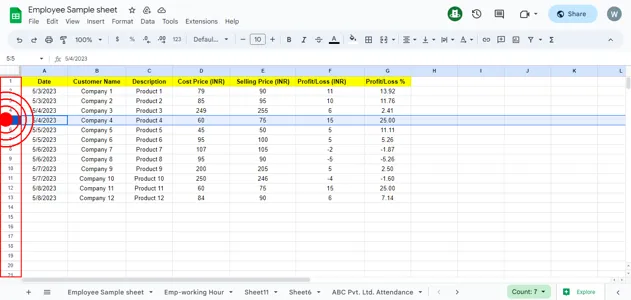
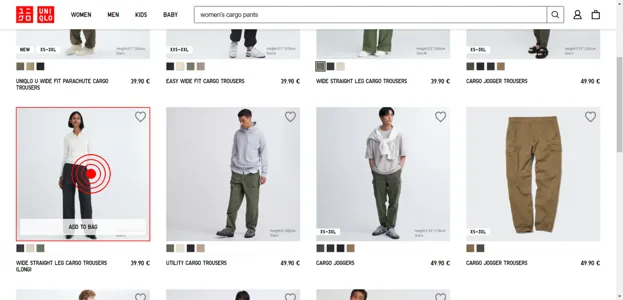
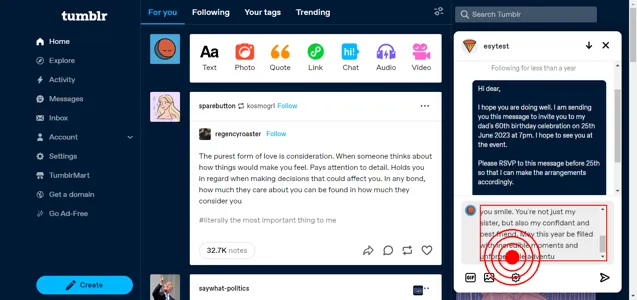

Conversational web navigation: What is it exactly?
We propose the problem of conversational web navigation, where a digital agent controls a web browser and follows user instructions to solve real-world tasks in a multi-turn dialogue fashion. To accomplish this, agents can learn from expert demonstrations, as shown below:
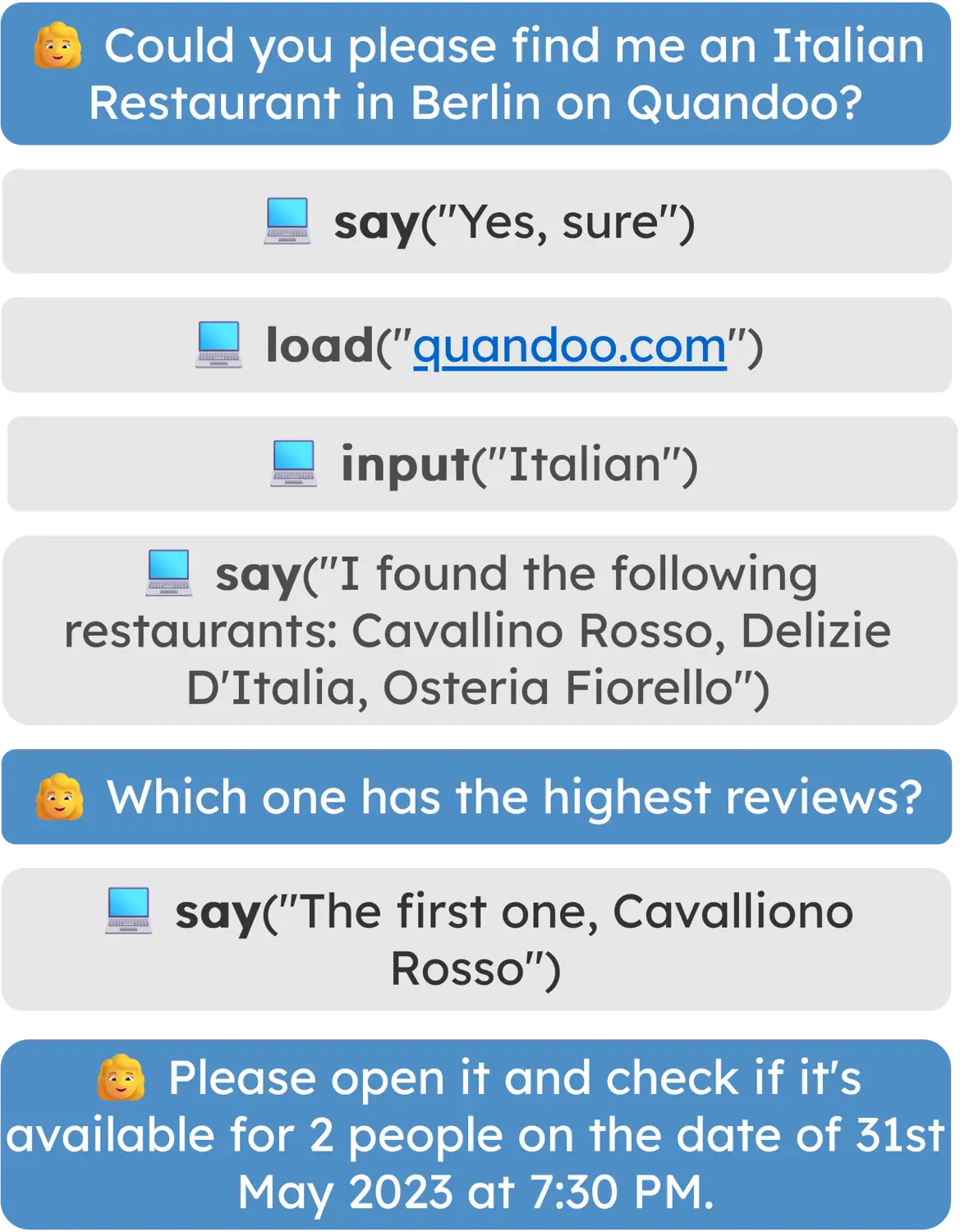
The digital agent may receive a system instruction, the HTML page, the action and conversation history, and the screenshot. The agent then needs to predict the next action to take.
Can we download WebLINX now?
You can find our dataset on Huggingface Datasets
You can download the training, valid and test sets using the following code:
from datasets import load_dataset
# Load the training, validation and test splits
train = load_dataset("McGill-NLP/weblinx", split="train")
val = load_dataset("McGill-NLP/weblinx", split="validation")
test = load_dataset("McGill-NLP/weblinx", split="test")
# Load one of the 4 out-of-domain splits (test_web, test_vis, test_geo, test_cat)
test_web = load_dataset("McGill-NLP/weblinx", split="test_web")
They can be directly used with LLMs or instruction-tuned text models.
How can we explore the dataset?
We provide the WebLINX Explorer, a tool to explore the dataset and see the interactions we have collected. You can use it to take a look at the dataset before diving in.
Check out the WebLINX Explorer on Huggingface Spaces
What if I want to download the raw data (HTML, screenshots, etc.)?
If you are interested in the full data, the easiest way to download the raw dataset is the use the huggingface_hub library with snapshot_download. We show you how in the doc’s prerequisite section.
If you want to learn the best ways process the raw dataset (prune HTML, format history, add instructions), you can use our weblinx Python library. It has tons of classes and functions to help you work with the dataset and build models. You can install it using pip:
# Basic installation
pip install weblinx
# Install all dependencies (evaluation, processing, etc.)
pip install weblinx[all]
Please take a look at the library documentation for more information on how to use it.
How can we use WebLINX to train agents?
Our agent is composed of two main components: a Dense Markup Ranker (DMR) and an action model.
First, we convert the HTML page into a compact representation. To do this, we use a specialized model called Dense Markup Ranker (DMR), which selects the most relevant elements in a HTML page, and discarding the rest.
We pass HTML, instructions, history and images to an action model (which can be a LLM or a multimodal model). The action model generates a string that represents the next action to take (e.g. click button, inserting text in form, load new page, respond to user). That string is parsed into a structured form that can be executed.
We experiment with 19 action models, ranging from smaller models (Flan-T5-MindAct, Pix2Act) to large chat-based models (LLaMA-13B, GPT-4-turbo) and multimodal models (Fuyu-8B, GPT-4V). You can find the results in the leaderboard.
Where can we find the finetuned models?
We provide the weights for the models we finetuned. You can access them on Huggingface Hub. We will share code to reproduce our experiments on our GitHub repository. Please note that they were finetuned for research purposes (so they are not ready for production).
How do we use the agent to control browsers?
Our weblinx library lets you convert the HTML into a format that can be received by DMR or by an action model, and weblinx can also parse valid model outputs into a dictionary that can be converted to browser commands.
You will need Selenium or Pupeteer to control the browser (take screenshot, grab HTML, insert unique IDs, execute action from dictionary); you can learn selenium here.
How do we cite WebLINX?
If you use our dataset, code, or models, please use the following bibtex citation entry:
@misc{lù2024weblinx,
title={WebLINX: Real-World Website Navigation with Multi-Turn Dialogue},
author={Xing Han Lù and Zdeněk Kasner and Siva Reddy},
year={2024},
eprint={2402.05930},
archivePrefix={arXiv},
primaryClass={cs.CL}
}